Pengertian Tree
Tree merupakan
salah satu bentuk struktur data tidak linear yang menggambarkan hubungan yang
bersifat hirarkis (hubungan one to many) antara elemen-elemen. Tree bisa
didefinisikan sebagai kumpulan simpul/node dengan satu elemen khusus yang
disebut Root dan node lainnya. Tree juga adalah suatu graph yang acyclic,
simple, connected yang tidak mengandung loop.
Sebuah binary
search tree (bst) adalah sebuah pohon biner yang boleh kosong, dan setiap
nodenya harus memiliki identifier/value. Value pada semua node subpohon sebelah
kiiri adalah selalu lebih kecil dari value dari root, sedangkan value subpohon
di sebelah kanan adalah sama atau lebih besar dari value pada root,
masing-masing subpohon tersebut (kiri dan kanan) itu sendiri adalah juga binary
search tree.
Struktur data bst
sangat penting dalam struktur pencarian, misalkan dalam kasus pencarian dalam
sebuah list, jika list sudah dalam keadaan terurut maka proses pencarian akan
semakin cepat, jika kita menggunakan list contigue dan melakukan
pencarian biner,akan tetapi jika kita ingin melakukan perubahan isi list
(insert atau delete), menggunakan list contigue akan sangat lambat, karena
prose insert dan delete dalam list contigue butuh memindahkan linked-list, yang
untuk operasi insert atau delete tinggal mengatur- atur pointer,akan tetapi
pada n-linked list, kita tidak bisa melakukan pointer sembarangan setiap saat,
kecuali hanya satu kali dengan kata lain hanya secara squential.secara
sederhana pohon bisa didefinisikan sebagai kumpulan elemen yangsalah satu
elemennya disebut dengan akar (root) dan elemen yang lainnya (simpul),terpecah
menjadi sejumlah himpunan yang saling tidak berhubungan satu dengan
yang lainnya.
Predecessor : node yang berada di atas node tertentu
Successor : node yang dibawah node tertentu
Ancestor : seluruh node yang terletak sebelum node
tertentu dan terletaksesudah pada jalur yang sama
Descendant :
seluruh node yang terletak sesudah node tertentu dan terletaksesudah
pada jalur yang sama
Parent : predecessor satu level diatas suatu node
Child : successor satu level dibawah suatu node
Sibling : node-node yang memiliki parent yang sama dengan suatunode
Subtree : bagian dari tree yang berupa suatu node beserta descendantnya
dan memiliki semua karakteristik dari tree tersebut
Size : banyaknya node dalam suatu tree
Height : banyaknya tingkatan/level dalam suatu tree
Root : satu-satunya node khusus dalam tree yang tidak mempunyaipredecessor
Leaf : node-node dalam tree yang tidak memiliki successor
Degree : banyaknya child yang dimiliki suatu node
Jenis-jenis Tree
Tree dengan syarat bahwa tiap node hanya
boleh memiliki maksimal duasubtree dan kedua subtree tersebut harus terpisah.
Maka tiap node dalam binarytree hanya boleh memiliki paling banyak dua
child.Keterangan :Left Child : B, D, H, ...Right Child : C, G, J, ...Jenis
Binary Tree :1.3.1.1
Binary Tree yang tiap nodenya (kecuali
leaf) memiliki dua child dan tiap sub treeharus mempunyai panjang path yang
sama : 1.3.1.2
Mirip dengan Full Binary Tree, namun tiap
subtree boleh memiliki panjang pathyang berbeda. Node kecuali leaf memiliki
0 atau 2 child 1.3.1.3
Binary Tree yang semua nodenya (kecuali
leaf) hanyamemiliki satu child. 1.3.2
Adalah binary search tree yang memiliki
perbedaan tingkat tinggi/level antarasubtree kiri dan subtree kanan maksimal
adalah 1. Dengan AVL Tree, waktupencarian dan bentuk tree dapat
dipersingkat dan disederhanakan.Selain AVL Tree terdapat juga Height Balanced n
tree, yaitu binary search treeyang memiliki perbedaan level antara subtree kiri
dan subtree kanan maksimaladalah n. Sehingga AVL Tree adalah Height Balanced 1
Tree.
Pengertian Graph
Graf adalah kumpulan noktah (simpul)
di dalam bidang dua dimensi yang dihubungkan dengan sekumpulan garis
(sisi).Graph dapat digunakan untuk merepresentasikan objek-objek diskrit
dan hubungan antara objek-objek tersebut. Representasi visual dari graph adalah
dengan menyatakan objek sebagai noktah, bulatan atau titik (Vertex), sedangkan
hubungan antara objek dinyatakan dengan garis (Edge). Graf merupakan suatu
cabang ilmu yang memiliki banyak terapan. Banyak sekali struktur yang bisa
direpresentasikan dengan graf, dan banyak masalah yang bisa diselesaikan dengan
bantuan graf. Seringkali graf digunakan untuk merepresentasikan suaru jaringan.
Misalkan jaringan jalan raya dimodelkan graf dengan kota sebagai simpul (vertex/node)
dan jalan yang menghubungkan setiap kotanya sebagai sisi (edge) yang bobotnya (weight)
adalah panjang dari jalan tersebut.
Ada beberapa cara untuk menyimpan graph di
dalam sitem komputer. Struktur data bergantung pada struktur graph dan
algoritma yang digunakan untuk memmanipulasi graph. Secara teori salah satu
dari keduanya dapat dibedakan antara struktur list dan matriks, tetapi dalam
penggunaannya struktur terbaik yang sering digunakan adalah kombinasi keduanya.
Graph tak berarah (undirected graph
atau non-directed graph)
Urutan simpul dalam sebuah busur
tidak dipentingkan. Misal busur e1 dapat disebut busur AB atau BA
Graph berarah (directed graph) :
Urutan simpul mempunyai arti. Misal busur
AB adalah e1 sedangkan busur BA adalah e8.
Graph Berbobot (Weighted Graph)
Jika setiap busur mempunyai nilai yang
menyatakan hubungan antara 2 buah simpul, maka busur tersebut dinyatakan
memiliki bobot.
Bobot sebuah busur dapat menyatakan
panjang sebuah jalan dari 2 buah titik, jumlah rata-rata kendaraan perhari yang
melalui sebuah jalan, dll. Istilah-istilah dalam graf
Kemudian terdapat istilah-istilah
yang berkaitan dengan graph yaitu:
Vertex
Adalah himpunan node / titik pada sebuah
graph.
Edge
Adalah himpunan garis yang menghubungkan
tiap node / vertex.
Adjacent
Adalah dua buah titik dikatakan
berdekatan (adjacent) jika dua buah titik tersebut terhubung dengan sebuah
sisi. AdalahSisi e3 = v2v3 insident dengan
titik v2 dan titik v3, tetapi sisie3 = v2v3 tidak insident dengan
titik v1 dan titik v4.
Titik v1 adjacent dengan
titik v2 dan titik v3, tetapi titik v1 tidakadjacent dengan
titik v4.
Weight

Adalah Sebuah graf G = (V, E) disebut
sebuah graf berbobot (weight graph), apabila terdapat sebuah fungsi
bobot bernilai real W pada himpunan E,
W : E ® R,
nilai W(e) disebut bobot untuk sisi
e, " e Î E. Graf berbobot tersebut dinyatakan pula
sebagai G = (V, E, W).
Graf berbobot G = (V, E, W) dapat
menyatakan
* suatu sistem perhubungan udara, di
mana
· V = himpunan kota-kota
· E = himpunan penerbangan langsung
dari satu kota ke kota lain
· W = fungsi bernilai real pada E
yang menyatakan jarak atau ongkos atau waktu
* suatu sistem jaringan komputer, di
mana
· V = himpunan komputer
· E = himpunan jalur komunikasi
langsung antar dua komputer
· W = fungsi bernilai real pada E
yang menyatakan jarak atau ongkos atau waktu
Path
Adalah Walk dengan setiap vertex
berbeda. Contoh, P = D5B4C2ASebuah walk (W) didefinisikan sebagai
urutan (tdk nol) vertex & edge. Diawali origin vertex dan diakhiri terminusvertex. Dan setiap 2 edge berurutan adalah series.
Contoh, W = A1B3C4B1A2.
Cycle
Adalah Siklus ( Cycle )
atau Sirkuit ( Circuit ) Lintasan yang berawal dan berakhir pada
simpul yang sama
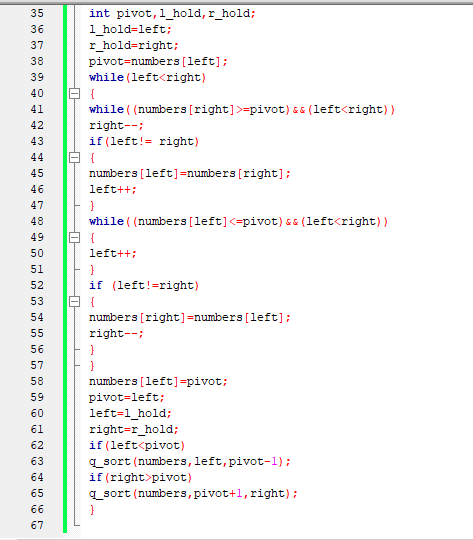
Source code Algoritma Dijkstra
Source code Algoritma Kruskal



Running
Source code Algoritma Dijkstra
Berikut merupakan source code untuk algoritma Dijkstra,
yaitu:
#include
<stdio.h>
#include
<stdlib.h>
#include
<iostream>
#define INF
999
using
namespace std;
int main()
{
int n,i,j,start;
printf("Masukan Jumlah Vertex :
");
scanf("%d",&n);
int
G[n][n],tempGraf[n][n],jarak[n],visit[n],temp[n],count;
printf("Masukan Matrix Graf :
\n");
for(i = 0;i < n ;i++)
{
for (j=0;j<n;j++)
{
cout<<"Matriks
["<<i<<"]["<<j<<"]: ";
scanf("%d",&G[i][j]);
}
}
printf("Masukan Vertex Asal : ");
scanf ("%d",&start);
for(i=0;i<n;i++)
{
for (j=0;j<n;j++)
{
if (G[i][j] == 0)
{
tempGraf[i][j] = INF;
}
else{
tempGraf[i][j] = G[i][j];
}
}
}
for (i = 0;i<n;i++)
{
jarak[i] = tempGraf[start][i];
temp[i] = start;
visit[i] = 0;
}
jarak[start] = 0;
visit[start] = 1;
count =1; //dimulai dari 1 karena kita
tidak akan menghitung vertex asal lagi
//proses untuk menghitung vertex yang
dikunjungi
int jarakmin,nextvertex;
while (count < n-1)
{
jarakmin = INF;
for (i=0;i<n;i++)
{
//jika jarak lebih kecil dari jarak
minimum dan vertex belum dikunjungi
// maka jarak minimum adalah jarak
yang sudah dibandingkan sebelumnya dengan jarakmin
if(jarak[i] < jarakmin
&& visit[i]!=1)
{
jarakmin = jarak[i];
nextvertex = i; //untuk
memberikan vertex pada jarak minimum
}
}
// untuk mengecek vertex selanjutnya
yang terhubung dengan vertex lain yang memiliki jarak minimum
visit[nextvertex] = 1;
for(i = 0;i<n;i++)
{
if(visit[i]!=1)
{
if(jarakmin+tempGraf[nextvertex][i]<jarak[i])
{
jarak[i] =
jarakmin+tempGraf[nextvertex][i];
temp[i] = nextvertex;
}
}
}
count++;
}
//nenampilkan jalur dan jarak untuk setiap
vertex
int a[n+1],k;
for (i = 0; i < n ;i++)
{
if(i!=start)
{
printf ("\nHasil jarak untuk
vertex ke-%d adalah %d\n",i,jarak[i]);
j=i;
printf ("%d<-",i);
while(j!=start)
{
j=temp[j];
printf ("%d",j);
if(j!=start)
{
printf ("<-");
}
}
}
}
printf ("\nTotal Jaraknya adalah
%d\n",jarak[n-1]);
return 0;
}
Source code Algoritma Kruskal
Berikut merupakan source code untuk algoritma Dijkstra,
yaitu:
#include
<cstdlib>
#include
<iostream>
#include
<fstream>
using
namespace std;
class
kruskal
{
private:
int n ;//no of nodes
int noe; //no edges in the graph
int graph_edge[100][4];
int tree[10][10];
int sets[100][10];
int top[100];
public:
int read_graph();
void initialize_span_t();
void sort_edges();
void algorithm();
int find_node(int );
void print_min_span_t();
};
int
kruskal::read_graph()
{
///cout<<"Program
ini Mengimplementasikan Algoritma Kruskal\n";
cout<<"Banyak
titik graph : ";
cin>>n;
noe=0;
cout<<"\nJarak
antar tiap titik:\n";
for(int
i=1;i<=n;i++)
{
for(int j=i+1;j<=n;j++)
{
cout<<"("<<i<<" ,
"<<j<<") = ";
int w;
cin>>w;
if(w!=0)
{
noe++;
graph_edge[noe][1]=i;
graph_edge[noe][2]=j;
graph_edge[noe][3]=w;
}
}
}
}
void
kruskal::sort_edges()
{
/** Sort
the edges using bubble sort in increasing order******/
for(int
i=1;i<=noe-1;i++)
{
for(int j=1;j<=noe-i;j++)
{
if(graph_edge[j][3]>graph_edge[j+1][3])
{
int t=graph_edge[j][1];
graph_edge[j][1]=graph_edge[j+1][1];
graph_edge[j+1][1]=t;
t=graph_edge[j][2];
graph_edge[j][2]=graph_edge[j+1][2];
graph_edge[j+1][2]=t;
t=graph_edge[j][3];
graph_edge[j][3]=graph_edge[j+1][3];
graph_edge[j+1][3]=t;
}
}
}
cout<<"\n\nSetelah
Jarak diurutkan adalah ::\n";
for(int
i=1;i<=noe;i++)
cout<<"("<<
graph_edge[i][1]
<<"
, "<<graph_edge[i][2]
<<"
) = "<<graph_edge[i][3]<<endl;
}
void
kruskal::algorithm()
{
for(int i=1;i<=n;i++)
{
sets[i][1]=i;
top[i]=1;
}
cout<<"\nRentang
Yang di Pakai\n\n";
for(int i=1;i<=noe;i++)
{
int p1=find_node(graph_edge[i][1]);
int p2=find_node(graph_edge[i][2]);
if(p1!=p2)
{
cout<<"Rentang yg masuk
ke pohon ::"
<<" <
"<<graph_edge[i][1]<<" , "
<<graph_edge[i][2]<<" > "<<endl<<endl;
tree[graph_edge[i][1]][graph_edge[i][2]]=graph_edge[i][3];
tree[graph_edge[i][2]][graph_edge[i][1]]=graph_edge[i][3];
// Mix the two sets
for(int j=1;j<=top[p2];j++)
{
top[p1]++;
sets[p1][top[p1]]=sets[p2][j];
}
top[p2]=0;
}
else
{
cout<<"Jika "
<<" <
"<<graph_edge[i][1]<<" , "
<<graph_edge[i][2]<<" > "<<"di
masukkan, maka terbentuk siklus. jadi di hapus\n\n";
}
}
}
int
kruskal::find_node(int n)
{
for(int i=1;i<=noe;i++)
{
for(int j=1;j<=top[i];j++)
{
if(n==sets[i][j])
return i;
}
}
return -1;
}
int
main(int argc, char *argv[])
{
kruskal obj;
obj.read_graph();
obj.sort_edges();
obj.algorithm();
system("PAUSE");
return EXIT_SUCCESS;
}
Maps
Berikut merupakan maps
yang diijadikan dasar oleh penyusun untuk dibuat graf pada kasus
pendistribusian obat ke apotek-apotek yang ada di Kota Pelaihari, yaitu:

Graph
Berikut merupakan graph pada algoritma Dijkstra
mengenai kasus pendistribusian obat
ke apotek-apotek yang ada di Kota
Pelaihari, yaitu:

Berikut merupakan graph pada algoritma Kruskal
mengenai kasus pendistribusian obat ke
apotek-apotek yang ada di Kota
Pelaihari, yaitu:

Matriks
1.
Matriks pada Algoritma Dijkstra
Berikut merupakan matriks yang terdapat pada algoritma
Dijkstra, yaitu:
|
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
|
0
|
0
|
255
|
0
|
0
|
0
|
0
|
0
|
0
|
1600
|
0
|
0
|
0
|
|
1
|
255
|
0
|
441
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
2
|
0
|
441
|
0
|
2760
|
0
|
0
|
0
|
0
|
1800
|
0
|
0
|
26
|
|
3
|
0
|
0
|
2760
|
0
|
7070
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
4
|
0
|
0
|
0
|
7070
|
0
|
5590
|
0
|
0
|
0
|
0
|
0
|
0
|
|
5
|
0
|
0
|
0
|
0
|
5590
|
0
|
1310
|
0
|
0
|
0
|
0
|
0
|
|
6
|
0
|
0
|
0
|
0
|
0
|
1310
|
0
|
656
|
0
|
1690
|
0
|
0
|
|
7
|
0
|
0
|
0
|
0
|
0
|
0
|
656
|
0
|
435
|
0
|
0
|
0
|
|
8
|
1600
|
0
|
1800
|
0
|
0
|
0
|
0
|
435
|
0
|
0
|
0
|
0
|
|
9
|
0
|
0
|
0
|
0
|
0
|
0
|
1690
|
0
|
0
|
0
|
20
|
0
|
|
10
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
20
|
0
|
30
|
|
11
|
0
|
0
|
26
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
30
|
0
|
2.
Matriks pada Algortima Kruskal
Berikut merupakan matriks yang terdapat pada algoritma Kruskal,
yaitu:
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
|
1
|
0
|
255
|
0
|
0
|
0
|
0
|
0
|
0
|
1600
|
0
|
0
|
0
|
|
2
|
255
|
0
|
441
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
3
|
0
|
441
|
0
|
2760
|
0
|
0
|
0
|
0
|
1800
|
0
|
0
|
26
|
|
4
|
0
|
0
|
2760
|
0
|
7070
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
5
|
0
|
0
|
0
|
7070
|
0
|
5590
|
0
|
0
|
0
|
0
|
0
|
0
|
|
6
|
0
|
0
|
0
|
0
|
5590
|
0
|
1310
|
0
|
0
|
0
|
0
|
0
|
|
7
|
0
|
0
|
0
|
0
|
0
|
1310
|
0
|
656
|
0
|
1690
|
0
|
0
|
|
8
|
0
|
0
|
0
|
0
|
0
|
0
|
656
|
0
|
435
|
0
|
0
|
0
|
|
9
|
1600
|
0
|
1800
|
0
|
0
|
0
|
0
|
435
|
0
|
0
|
0
|
0
|
|
10
|
0
|
0
|
0
|
0
|
0
|
0
|
1690
|
0
|
0
|
0
|
20
|
0
|
|
11
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
20
|
0
|
30
|
|
12
|
0
|
0
|
26
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
30
|
0
|
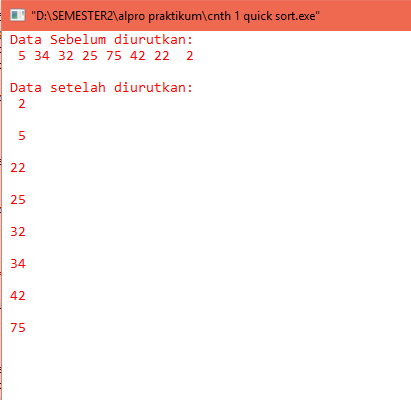
Running
1.
Hasil running
pada Algoritma Dijkstra
Berikut merupakan hasil running
yang terdapat pada algoritma Dijkstra, yaitu:

2.
Hasil running
pada Algoritma Kruskal
Berikut merupakan hasil running
yang terdapat pada algoritma Kruskal, yaitu:



Kesimpulan
Algoritma Kruskal adalah algoritma untuk
mencari pohon merentang minimum secara langsung didasarkan pada algoritma MST (Minimum spanning tree) umum. Pada
algoritma Kruskal sisi-sisi di dalam graf diurut terlebih dahulu berdasarkan
bobotnya dari kecil ke besar. Sisi yang dimasukkan ke dalam himpunan T adalah
sisi graf G sedemikian sehingga T adalah pohon. Pada keadaan awal, sisi-sisi
sudah diurut berdasarkan bobot membentuk hutan (forest). Hutan tersebut
dinamakan hutan merentang (spanning forest). Sisi dari graf G ditambahkan ke T
jika tidak membentuk sirkuit di T.
Algoritma Dijkstra, (penemunya adalah
seorang ilmuwan komputer, Edsger Dijkstra), adalah sebuah algoritma yang
dipakai dalam memecahkan permasalahan jarak terpendek untuk sebuah graph
berarah dengan bobot-bobot sisi yang bernilai positif.
Berdasarkan penelitian yang telah
dilakukan, dapat disimpulkan bahwa
program algoritma djikstra maupun algoritma kruskal sangat
membantu didalam menemukan data berupa jarak yang terdekat sehingga dapat
menambah efisiensi waktu dalam pencarian tempat yang terdekat yang akan dituju.
Dari kedua program ini, algoritma kruskal lebih unggul daripada algoritma
djikstra, karena didalam algoritma kruskal tidak terjadi penginputan yang
berulang (prinsipnya misalkan 1,2 = 2,1), sedangkan program algoritma djikstra
selalu melakukan penginputan yang berulang (prinsipnya misalkan 1,2 ≠ 2,1).
Dengan adanya prinsip seperti ini, tentu sangat mempengaruhi dalam waktu untuk
pencarian data berupa jarak yang terdekat
Sumber
Fajri,
D. (n.d.). TREE.
https://www.academia.edu/32724486/LAPORAN_PRAKTIKUM_6_ALGORITMA_STRUKTUR_DATA-TREE.
Ilmu, B. (2015). ALGORITMA TREE (POHON).
http://algoritmatree140403020020.blogspot.com/2015/01/algoritma-tree-pohon-minggu-04-januari.html.
Kirana, A. P. (n.d.). GRAPH.
https://www.academia.edu/25537594/GRAPH_Matakuliah_Algoritma_dan_Struktur_Data.
Ruri. (2013). graph dan tree.
http://informatikaipbruri.blogspot.com/2013/01/graph-dan-tree.html.
Siswantara, H. (2013). ALGORITMA DAN STRUKTUR DATA
“TREE”.
https://sumbersinau.wordpress.com/2013/04/30/algoritma-dan-struktur-data-tree/.